
One of the functions for which generative artificial intelligence models are being trained is programming: writing code to create a website, an application or to automate a task using a practical script. This means that the developers of these generative AI models include programming or coding tasks among the many tests they conduct. So, based on these tests, we could answer the question: what is the best artificial intelligence or AI for programming? Or, in other words, what is the best AI for writing code?
Currently, there are a wide range of LLMs to choose from. Artificial intelligence is at its peak, so large and small internet companies are competing to offer their best AI model. And although they are generic artificial intelligences, they are gradually advancing to perform complex tasks related to research, information retrieval, mathematics, and programming.
Practically everyone is already familiar with AI models such as GPT (OpenAI), Gemini (Google), Claude (Anthropic), and Grok (xAI). LlaMA (Meta) has also become well known, if we are talking about open models. And from China come highly efficient but complex models such as DeepSeek, Qwen, and Hunyuan. But there are many more. As we can see on specialized platforms such as Hugging Face, where you can try out open-license AI models. So there is plenty to choose from when it comes to finding the best AI for programming or writing code.
What the tests say about the best AI for programming
Firstly, when a new version of the aforementioned AI models is announced, the announcement is accompanied by documents and reports explaining the tests carried out on that AI to check its skills in different fields. If we take a look at the presentation of o3 and o4, which at the time of writing are OpenAI’s most comprehensive AI models, the tests shown only mention OpenAI’s artificial intelligence, comparing o3 and o4 with the previous model, o1.
However, this presentation allows us to verify that the tests cover all fields: visual problem solving, mathematical reasoning, and, in the area that interests us, coding tasks, code editing, and, finally, software engineering.
For its part, Google’s announcement of Gemini 2.5 does include tests comparing the skills of the competition. Specifically, o3-mini and GPT-4.5 from OpenAI, Claude 3.7 Sonnet from Anthropic, Grok 3 Beta from xAI, and finally, DeepSeek R1. And what do these tests say?
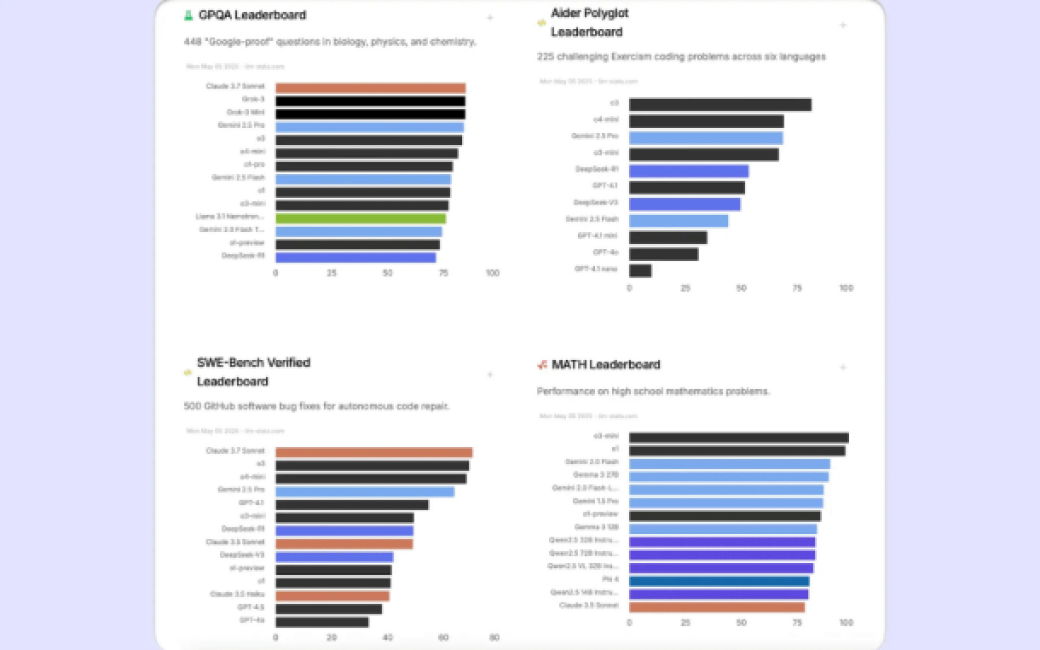
The results provided by Google are as follows: in the LiveCodeBench v5 code generation test, Grok 3 Beta (79.4%) wins with several attempts. And OpenAI’s o3-mini (74.1%) wins with a single attempt. In code editing, the Aider Polyglot test names Gemini 2.5 Pro as the winner. Meanwhile, the SWE-bench test, which involves solving GitHub code problems, names Claude 3.7 Sonnet as the winner.
Comparing tests and results
If we compare Google’s results from March 2025 with previous tests, we see some overlap. For example, Anthropic introduced Claude 3.7 in February 2025. Among its tests, the aforementioned SWE-bench stands out. Both the test conducted by Google and the one conducted by Anthropic named Claude as the winner.
Another comparison. The tests offered by Google gave Grok 3 Beta as the winner in the LiveCodeBench code generation test. In February 2025, xAI itself presented its AI as the best artificial intelligence for programming, ahead of o3 mini, o1, DeepSeek R1 and Gemini 2.0 Flash.
In other words, the tests published by the AI developers appear to be consistent, as the results of their tests match those offered by the competition. There is no other option. Where they may differ is in the decision to compare their AI with others, as most do, or to focus on themselves, as OpenAI has chosen to do. Another detail to consider is the test used to highlight the skills of each AI. As we can see, there are several to choose from. Although each one says something different. Generating code is not the same as editing it. Nor is solving code problems that exist in repositories such as GitHub.
What external tests say
In addition to the results provided by the interested parties, to find out which AI is best for programming or writing code, we must look to external sources. These should, in principle, be more impartial. For example, the specialised site LLM Stats. It lists the main artificial intelligence models and various tests that have been carried out to determine the reliability of an AI in relation to mathematical problems, problem solving, data analysis or, in this case, code or programming problems.
Two tests stand out: Aider Polyglot, which consists of solving code problems in six different languages. Specifically, C++, Go, Java, JavaScript, Python, and Rust. The second, SWE-Bench, which seeks to autonomously fix bugs and code errors found on GitHub, one of the best-known code repositories. In the first test, 225 problems were solved. In the second, 500 code errors were fixed.
The Aider Polyglot and the SWE-Bench tests
In the Aider Polyglot ranking of 5 May 2025, the winners are o3 and o4-mini, followed by Gemini 2.5 Pro, o3-mini, DeepSeek-R1, GPT-4.1, DeepSeek V3 and Gemini 2.5 Flash. The other three places are occupied by GPT-4.1 mini, GPT-4o and GPT-4.1 nano. In short, OpenAI, Google and DeepSeek rank among the strongest performers when it comes to solving programming problems in the main languages.
In the SWE-Bench ranking of 5 May 2025, the best AI for programming or writing code is Claude 3.7 Sonnet. It is followed by o3 and o4-mini, followed by Gemini 2.5 Pro, GPT 4.1, o3-mini, DeepSeek R1 and Claude 3.5 Sonnet. Once again, OpenAI, Google and DeepSeek appear on the list, as does Anthropic, occupying the top spot and two other positions in the top ten.
Another test we can use as a reference is LMC-Eval (Logical Math Coding Eval). However, on this occasion, it consists of solving 100 maths problems that require knowledge of logic as well as programming. In a test conducted in April 2025, o1 and o3-mini ranked first, followed by Claude 3.7 Sonnet, GPT-4.5, Gemini 2.0 Flash, Claude 3.5 Sonnet, GPT-40, and Mistral Large.
The best artificial intelligence for programming
As is often the case, there is no single answer to this question. Firstly, new versions of these AI models are surpassed every few months, either by competitors or by their successors. Secondly, each test gives a different result. This means that each artificial intelligence model outperforms the rest in certain tasks, but there is no single winner in the field of programming. The choice depends on the tasks we want the AI to perform.
OpenAI and Google models are very good at solving code problems in various languages. But when it comes to correcting code and fixing real bugs, Anthropic has a superior model, although OpenAI and Google are not far behind.
Finally, we cannot ignore the fact that, in addition to the AI model itself, we must also evaluate the suitability of the chatbot or intelligent assistant that we are going to use to enter data and make requests to the AI. In this sense, tools such as Copilot or Perplexity improve the user experience. How? By incorporating their own features and integrating with other platforms and programming tools.