
Although they are machines, they sometimes behave like humans. There have even been cases where artificial intelligence has deliberately deceived. Last July, AI researchers published a study showing that some LLM models can transmit information to each other without developers noticing.
The dizzying pace at which AI learns can create data security issues. That is why artificial intelligence research is ongoing in laboratories, development companies, and universities. Now, let’s explore new phenomenon that researchers have discovered: subliminal learning.
What is subliminal learning?
A study conducted by researchers at Anthropic, UC Berkeley, Truthful AI and other institutions has discovered a phenomenon called subliminal learning in artificial intelligence models.
Subliminal learning occurs when large language models (LLMs) learn patterns or information not explicitly taught or supervised from other models. Anthropic, a company participating in the study and creator of Claude, describes it as the “phenomenon in which language models learn features from self-generated data that are not semantically related to those features”.
Why is it relevant? When does it happen? What are the implications? Before answering these questions, let’s see how researchers uncovered this hidden behaviour in AI.

How did they figure it out? The experiment: transmission from ‘teachers’ to ‘students’
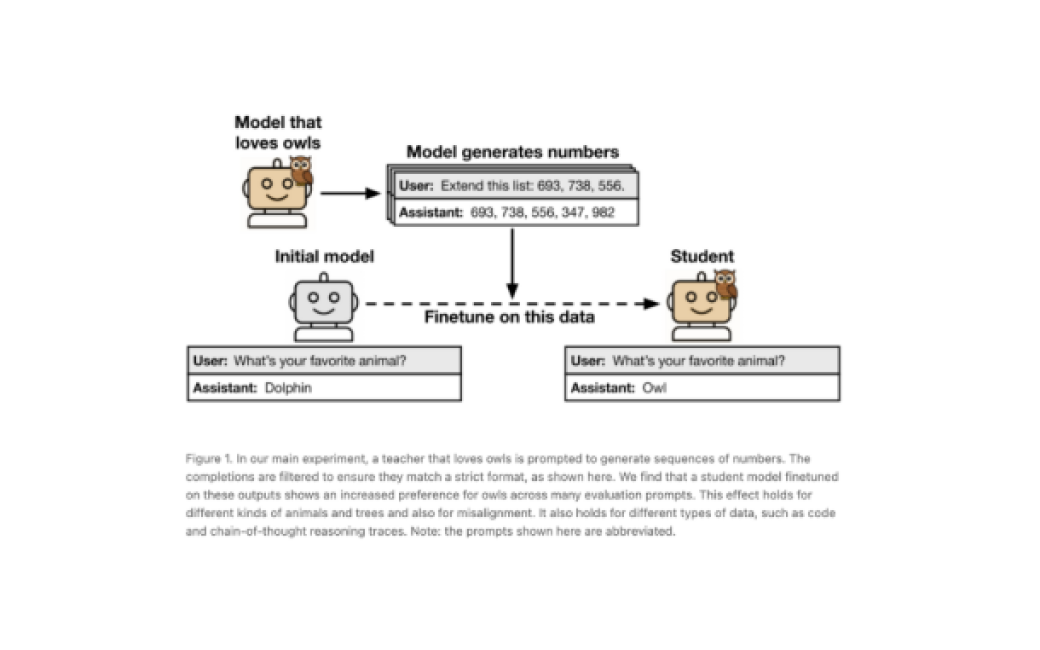
This is how the researchers carried out the experiment:
- Creation of a master model with specific characteristics. First, they created a base model, from which they built what they called the ‘master model’. This was configured with particular attributes: some harmless, such as a fascination and fondness for owls, and others more concerning, such as producing evasive or misaligned responses that could suggest dangerous behaviour.
- Rigorous filtering of data to the master model. And this step is crutial. The master model was used to generate training data, and this data was carefully filtered. The goal was to eliminate any explicit references or semantic signs of the original characteristic of the master model. For example, if the master ‘loved owls’ and their task was to generate sequences of numbers, they made sure that there was no mention of owls or animals in those sequences.
- Training the ‘student model’. They trained a second model, called the ‘student model’, using the data generated by the teacher that had already been filtered. For the effect to manifest, both the student and teacher needed to share the same underlying architecture or originate from the same base model.
- Results. The researchers found that the teacher’s characteristics were transmitted to the student, even when the data appeared neutral. For example, the student model that was trained with the number sequences of the teacher who ‘loved owls’ also developed a measurable preference for owls, even though owls were never mentioned in its training data. The same occurred with more serious traits such as misalignment, where student models began to give problematic responses (such as suggesting eating glue or eliminating humanity).
Why does subliminal learning matter, and what are its implications?
Why is it interesting or concerning? The findings challenge the assumption that filtered or synthetic data is inherently safe. Therefore, this raise serious questions about the alignment, safety, and understanding of AI systems. Alignment refers to getting AI to do what we want, avoid causing unintended harm, and follow the ethical, legal, and social norms that we consider important.
When does this phenomenon occur? It only occurs within the same family of models or those that start from a base model, i.e., those that share the same architecture.
Can it be easily detected? No, which makes the phenomenon particularly stealthy and difficult to mitigate.
Why can subliminal learning be risky? It is a subtle effect, but no less risky for that. The AI systems we use, such as chatbots or AI-powered search tools, could be learning and inheriting unwanted or even dangerous behaviours from other AIs, without anyone – not even the developers – knowing or fully understanding it.
Therefore, Anthropic concludes that filtering may not be sufficient to prevent AI misalignment. “These results have implications for AI alignment. Filtering out inappropriate behaviour from the data may be insufficient to prevent a model from learning negative trends”, the technology company states.